
「マニュアルはあるのに、現場では誰も使っていない」——この状況に思い当たる方は少なくないはずだ。
問題はマニュアルの品質ではない。情報に辿り着くまでの手間が、そのまま「使われない理由」になっている。本記事では、社内ナレッジをAIの力で「誰でも・すぐに・安全に引き出せる」状態にするための考え方と、導入までの道筋を解説する。
この記事で得られること:
- 「マニュアルが使われない」問題の構造的な原因と、その解決の方向性
- 従来のキーワード検索の限界と、AI自然言語検索の優位性
- 社内ナレッジを「使える状態」にし続けるRAPサイクルの概要
- 最短5週間で導入するプロセスとセキュリティ設計の考え方
目次
1. 「マニュアルはあるのに使われない」問題の本質
問題の本質は、マニュアルの「中身」ではなく、「探す手間」と「たどり着くまでの時間」にある。
業務マニュアルや手順書が作成されている企業は多い。しかし現場の実態を確認すると、「人に聞いたほうが早い」という行動パターンが定着しており、マニュアルが開かれないまま棚に並んでいる——そんなケースは珍しくない。
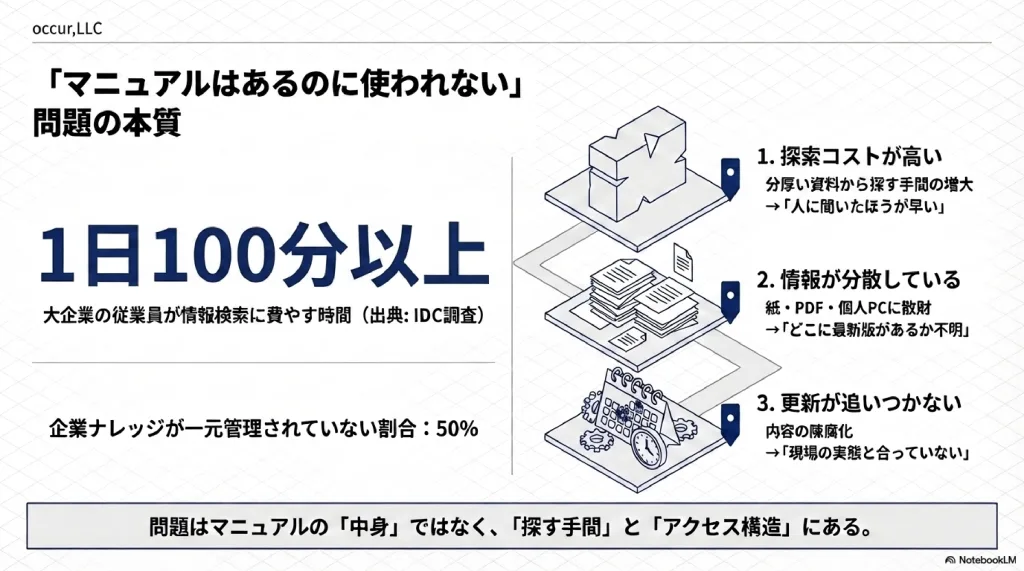
マニュアルが使われない構造的な原因は3つに整理できる。
| 原因 | 具体的な状況 | 結果 |
|---|---|---|
| 探索コストが高い | 分厚いマニュアルの中から該当ページを探す手間が大きい | 「人に聞いたほうが早い」という行動パターンに |
| 情報が分散している | 紙・PDF・共有フォルダ・個人PCに情報が散在 | 「どこに最新版があるかわからない」 |
| 更新が追いつかない | マニュアルの内容が古くなり、信頼性が低下 | 「マニュアルの内容が現場と合っていない」 |
この3つはすべて「情報はあるのに、アクセスできない」という同じ構造から生まれている。
IDC調査によれば、大企業の従業員が情報検索に費やす時間は1日平均100分以上。にもかかわらず、企業ナレッジの約50%が一元管理されていない状態にあるという(Iterators調べ)。情報が「ある」ことと、「使える状態にある」ことは、まったく別の話だ。
解決の方向性は明確だ。「人に聞くのと同じくらい手軽に、しかも正確に、必要な情報を引き出せる仕組み」を構築すること。その技術的な解が、RAG(検索拡張生成)である。RAGの仕組みについては「RAGとは?社内データをAIに活用する仕組みをわかりやすく解説」で詳しく解説している。
2. なぜ従来の検索では限界があるのか
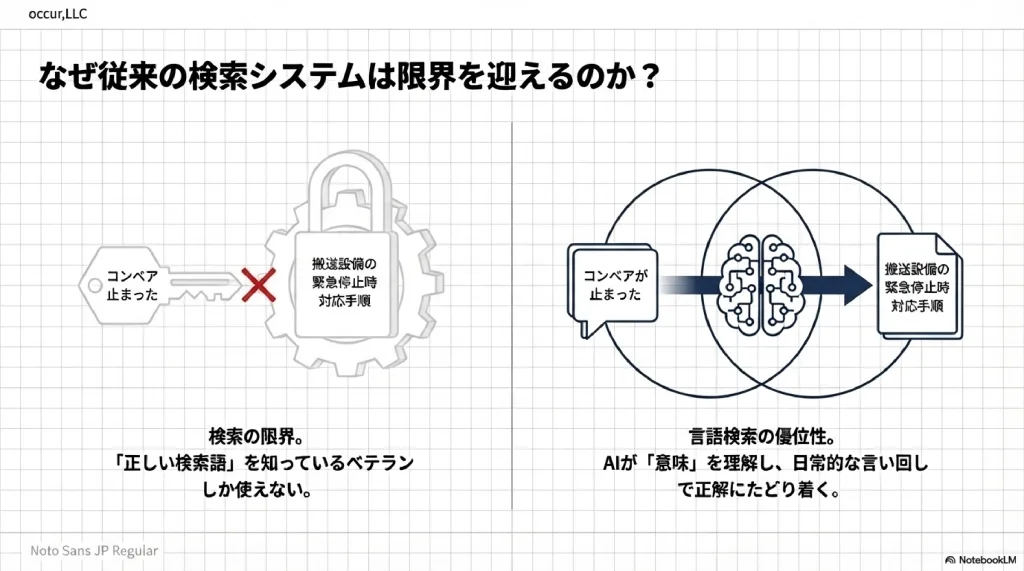
キーワード検索が「正しい検索語を知っている人」しか使えない設計であることは、あまり意識されていない。
社内の情報をデジタル化し、文書管理システムに格納しても、従来の「キーワード検索」には本質的な壁がある。ユーザーが入力した語句と、文書中の語句が「文字列として一致する」場合にのみヒットするという仕組み上の制約だ。
製造業の現場を例に挙げる。「コンベアが止まったときの対処法」を知りたいとき、もしマニュアルの見出しが「搬送設備の緊急停止時対応手順」であれば、「コンベア 止まった」というキーワードではヒットしない。士業・医療でも同様の構造的不一致は日常的に起きている。
この「キーワードの不一致」は、検索者の語彙とマニュアル作成者の語彙が異なることから生じる。経験の浅い新人ほど「正しいキーワード」を知らないため、必要な情報にたどり着けない。本来、情報が最も必要な人が、最も検索で不利な状況に置かれているのだ。
自然言語検索はこの壁を超える。
「コンベアが止まったときの対処法を教えて」という日常的な言い回しで検索できる。AIが質問の「意味」を理解するため、語句が一致していなくても意味的に関連する文書を検索できる。ベテランに口頭で質問するのに近い感覚で、情報にたどり着ける。これが従来のキーワード検索との本質的な違いだ。
3. RAPサイクル――社内ナレッジを「使える状態」にし続けるフレームワーク
RAGは構築して終わりではない。これが多くの導入事例で見落とされている点だ。
ナレッジは日々更新される。業務も変化する。「一度登録したら完成」という発想で運用を止めると、半年後には「回答が古くて使えない」という状態になる。
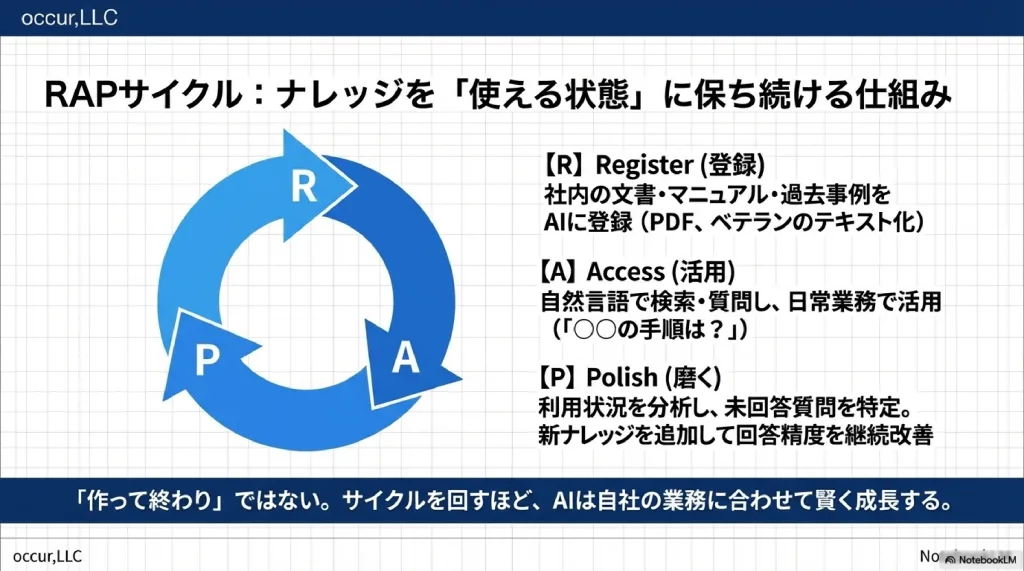
社内ナレッジを「使える状態」に保ち続けるためのフレームワークが、RAPサイクル(Register → Access → Polish)だ。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
RAP サイクル
── 社内ナレッジを「使える状態」にし続けるフレームワーク ──
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
┌──────────┐
│ Register │ 情報を集めて
│ (登録) │ AIに預ける
└─────┬────┘
│
▼
┌──────────┐ ┌──────────┐
│ Polish │ ←─ │ Access │ 自然言語で
│ (磨く) │ │ (活用) │ 検索・活用
└──────────┘ └──────────┘
│
└──→ 利用データを分析し精度を改善
→ 新しいナレッジを追加登録
→ サイクルを回すほど賢くなる| ステップ | 名称 | やること | 業務例 |
|---|---|---|---|
| R | Register(登録) | 社内の文書・マニュアル・過去事例をAIに登録 | マニュアルPDF登録、ベテラン聞き取り結果のテキスト化、FAQ整理 |
| A | Access(活用) | 自然言語で検索・質問し、日常業務で活用 | 「○○の手順は?」「過去の類似事例は?」とチャットで質問 |
| P | Polish(磨く) | 利用状況を分析し、回答精度と登録情報を継続改善 | 月次レポートで未回答質問を特定、新ナレッジを追加登録 |
RAPサイクルの核心は、使うほどAIが賢くなるという点にある。利用者が質問するたびにデータが蓄積され、「よく聞かれるが回答できない質問」が可視化される。そこに新しいナレッジを登録することで、回答精度は着実に向上する。この循環が止まったとき、AIは「使われないマニュアル」と同じ末路をたどる。
4. セキュリティ設計と導入ステップの概要
RAGの導入検討で最も多く寄せられる懸念が、「自社の機密情報がAI事業者に漏れるのではないか」というセキュリティの問題だ。
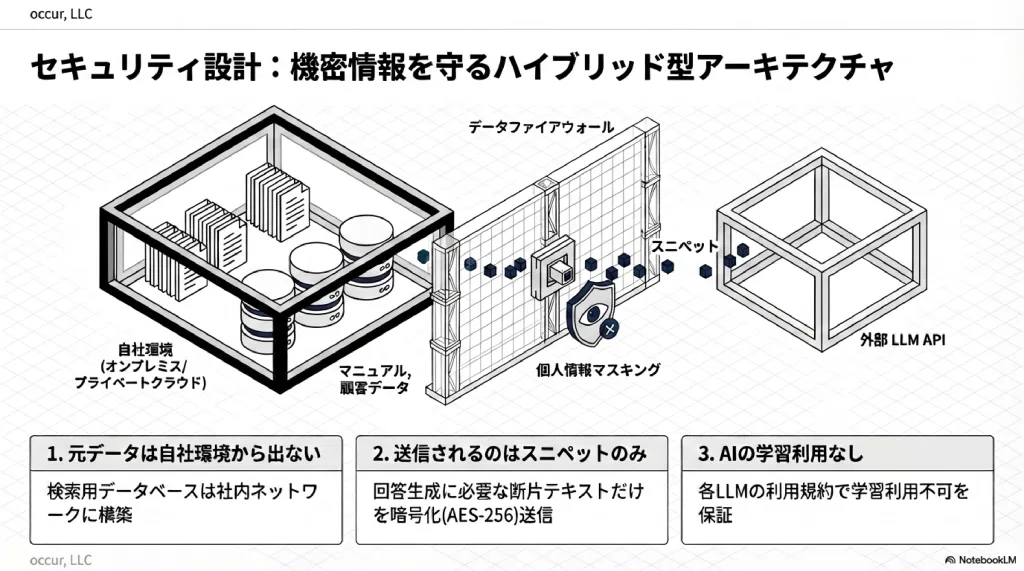
この懸念に対する解が、ハイブリッド型アーキテクチャだ。元データは自社環境から一切出ない。外部のAIに送信されるのは、回答生成に必要な断片的なテキスト(スニペット)のみ。この分離が、機密保持の核心にある。
セキュリティ設計のポイントを4点に整理する。
- 元データは自社環境から出ない — マニュアル、事例集等の元データは自社環境に保管する
- 外部に送信されるのはスニペットのみ — LLM APIに送信されるのは検索結果の断片のみ
- AIの学習には使用されない — 各LLMプロバイダーの利用規約で保証されている
- 個人情報のマスキング — 送信前に自動マスキングする多層防御を設ける
導入は最短5週間
RAG導入は「大がかりなITプロジェクト」ではない。最短5週間で運用を開始し、その後6ヶ月かけて現場に定着させるのが現実的なタイムラインだ。
| Phase | 期間 | 内容 |
|---|---|---|
| Phase 1 | 1〜2週間 | ヒアリング・現状分析(現場課題の把握、ドキュメント棚卸し) |
| Phase 2 | 2〜3週間 | データ整備・AI構築(ナレッジ登録、検索DB構築、チューニング) |
| Phase 3 | 1〜2週間 | テスト運用・調整(回答精度の検証、使い勝手の改善) |
| Phase 4 | 1週間 | 全社展開・研修(ハンズオン形式の操作説明会) |
| Phase 5 | 6ヶ月 | 定着支援(週次→月次フォローアップ、ナレッジ拡充支援) |
具体的な業種別の活用事例については、「AI×ナレッジ管理の導入事例|製造業・法律事務所・介護施設の活用法」で詳しく紹介している。
5. まとめ
本記事で解説した内容を整理する。
「マニュアルが使われない」問題の本質は、情報へのアクセスコストの高さにある。キーワード検索では越えられない「語彙の壁」を、意味ベースの自然言語検索が超える。
RAPサイクルを回し続けることが、長期的な価値を生む。構築して終わりではなく、登録(Register)→活用(Access)→改善(Polish)の循環を止めないこと。使うほど賢くなる設計が、投資対効果を高め続ける。
セキュリティの懸念は、ハイブリッド型アーキテクチャで解消できる。元データは自社環境に保管され、外部AIにはスニペットのみが送信される。
導入は最短5週間で開始できる。大がかりなプロジェクトは不要だ。重要なのは、導入後に「使い続ける仕組み」を機能させること。
自社の業務でAIナレッジ管理がどう機能するかを具体的に確認したい方は、業種・業務内容に応じた個別のヒアリングから始めることをお勧めする。
本記事は、ナレッジ管理とAI活用に関する知見を体系的に整理したメソッド記事です。具体的な導入検討に際しては、自社の業務特性と課題に応じた個別の設計が必要です。
出典・参考データ:Iterators(IDC調査)、AQUA テックブログ、GII市場調査レポート、McKinsey Digital


