
「マニュアルはあるのに、現場では誰も使っていない」——この状況に思い当たる方は少なくないはずだ。
問題はマニュアルの品質ではない。情報に辿り着くまでの手間が、そのまま「使われない理由」になっている。本記事では、社内ナレッジをAIの力で「誰でも・すぐに・安全に引き出せる」状態にするための具体的な手順を、経営者やDX推進担当者に向けて技術用語を極力使わずに解説する。
この記事で得られること:
- 「マニュアルが使われない」問題の構造的な原因と、その解決の方向性
- RAG(検索拡張生成)の仕組みを、専門用語なしで理解できる解説
- 最短5週間で導入する具体的なプロセスとセキュリティ設計の考え方
目次
- 「マニュアルはあるのに使われない」問題の本質
- なぜ従来の検索では限界があるのか
- RAGとは何か――「自社データで回答するAI」をわかりやすく解説
- RAPサイクル――社内ナレッジを「使える状態」にし続けるフレームワーク
- セキュリティ設計――ハイブリッド型アーキテクチャの仕組み
- 導入の具体的なステップ(最短5週間の導入プロセス)
- 3業種の具体的な活用シーン
- まとめ
1. 「マニュアルはあるのに使われない」問題の本質
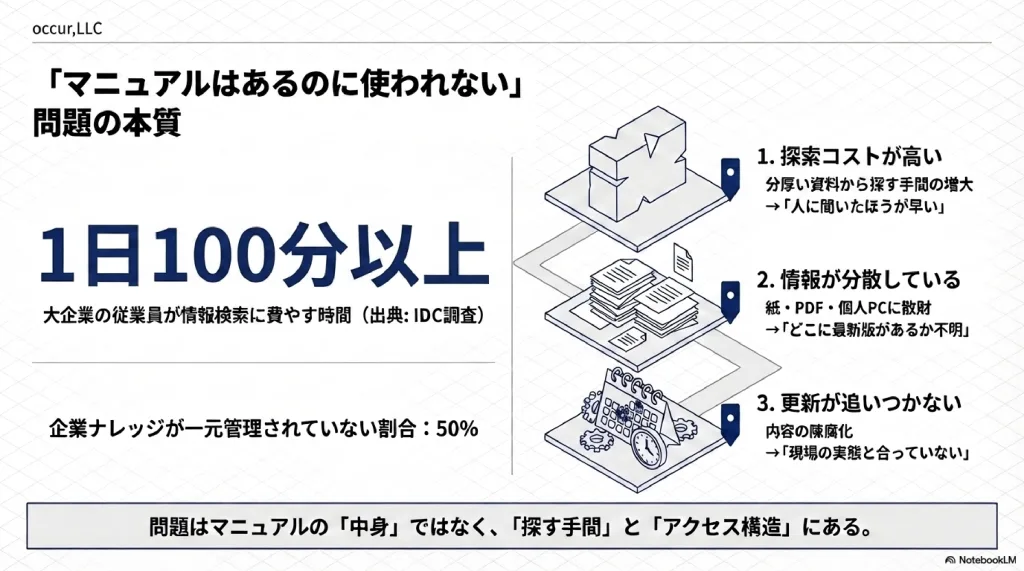
問題の本質は、マニュアルの「中身」ではなく、「探す手間」と「たどり着くまでの時間」にある。
業務マニュアルや手順書が作成されている企業は多い。しかし現場の実態を確認すると、「人に聞いたほうが早い」という行動パターンが定着しており、マニュアルが開かれないまま棚に並んでいる——そんなケースは珍しくない。
マニュアルが使われない構造的な原因は3つに整理できる。
| 原因 | 具体的な状況 | 結果 |
|---|---|---|
| 探索コストが高い | 分厚いマニュアルの中から該当ページを探す手間が大きい | 「人に聞いたほうが早い」という行動パターンに |
| 情報が分散している | 紙・PDF・共有フォルダ・個人PCに情報が散在 | 「どこに最新版があるかわからない」 |
| 更新が追いつかない | マニュアルの内容が古くなり、信頼性が低下 | 「マニュアルの内容が現場と合っていない」 |
この3つはすべて「情報はあるのに、アクセスできない」という同じ構造から生まれている。
IDC調査によれば、大企業の従業員が情報検索に費やす時間は1日平均100分以上。にもかかわらず、企業ナレッジの約50%が一元管理されていない状態にあるという(Iterators調べ)。情報が「ある」ことと、「使える状態にある」ことは、まったく別の話だ。
解決の方向性は明確だ。「人に聞くのと同じくらい手軽に、しかも正確に、必要な情報を引き出せる仕組み」を構築すること。その技術的な解が、後述するRAGである。
2. なぜ従来の検索では限界があるのか
キーワード検索が「正しい検索語を知っている人」しか使えない設計であることは、あまり意識されていない。
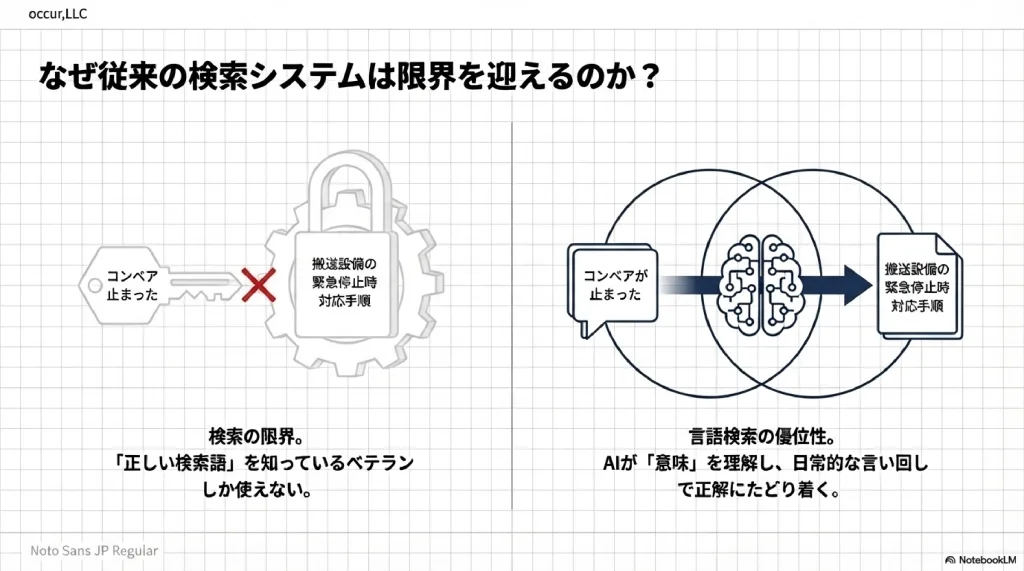
社内の情報をデジタル化し、文書管理システムに格納しても、従来の「キーワード検索」には本質的な壁がある。ユーザーが入力した語句と、文書中の語句が「文字列として一致する」場合にのみヒットするという仕組み上の制約だ。
製造業の現場を例に挙げる。「コンベアが止まったときの対処法」を知りたいとき、もしマニュアルの見出しが「搬送設備の緊急停止時対応手順」であれば、「コンベア 止まった」というキーワードではヒットしない。士業・医療でも同様の構造的不一致は日常的に起きている。
この「キーワードの不一致」は、検索者の語彙とマニュアル作成者の語彙が異なることから生じる。経験の浅い新人ほど「正しいキーワード」を知らないため、必要な情報にたどり着けない。本来、情報が最も必要な人が、最も検索で不利な状況に置かれているのだ。
自然言語検索はこの壁を超える。
「コンベアが止まったときの対処法を教えて」という日常的な言い回しで検索できる。AIが質問の「意味」を理解するため、語句が一致していなくても意味的に関連する文書を検索できる。ベテランに口頭で質問するのに近い感覚で、情報にたどり着ける。これが従来のキーワード検索との本質的な違いだ。
3. RAGとは何か――「自社データで回答するAI」をわかりやすく解説
ChatGPT等の汎用AIとの違い
ChatGPTやClaudeといった汎用AIは、インターネット上の膨大な情報をもとに「一般的な知識」で回答する。しかし、「御社のマニュアルに書いてある手順」や「過去に御社で発生したトラブルの対処法」は知らない。
汎用AIに社内のことを質問すると、一般論で答えるか、あるいは事実と異なる回答(ハルシネーション)を生成するリスクがある。汎用AIの問題は「嘘をつく」ことではなく、「御社のことを何も知らないまま、知っているように答えてしまう」ことだ。
RAG(Retrieval-Augmented Generation:検索拡張生成)は、この問題を解決する仕組みである。
RAGの動作原理
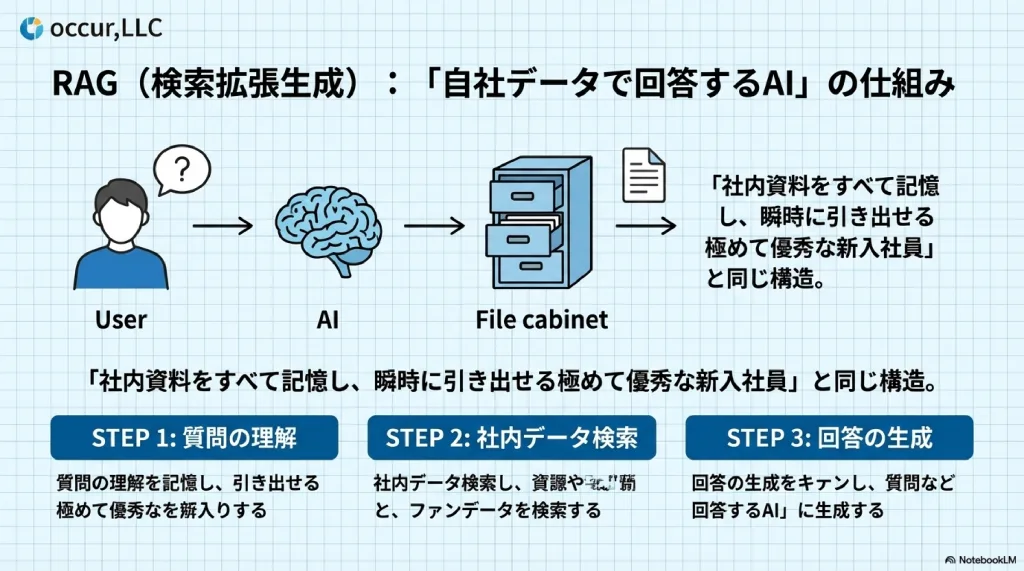
RAGは3つのステップで動作する。
ステップ1: 質問の理解
ユーザーが入力した質問の「意味」をAIが解析する。
ステップ2: 社内データベースからの検索
質問の意味をもとに、社内のナレッジベース(マニュアル・事例集・対応履歴等)から関連性の高い情報を検索する。
ステップ3: 回答の生成
検索結果をもとに、AIが回答を生成する。根拠となる社内データが明示されるため、汎用AIのような「なんとなくそれらしい回答」ではなく、「御社の情報に基づいた回答」が返ってくる。
わかりやすくたとえるなら、「非常に優秀な新入社員」だ。入社初日は何も知らないが、社内のマニュアルや資料をすべて読み込み、必要なときに瞬時に参照して回答できる——それがRAGの設計思想に近い。ナレッジベースに新しい情報を追加すれば、即座にAIの回答に反映される点も、人間の新入社員にはない強みだ。
「汎用AI」vs「業務特化AI(RAG)」

【パターンA: ChatGPT単体(汎用AI)】
社員の質問 回答
「うちの溶接工程の ──→ 「一般的な溶接の注意点は
注意点は?」 以下の通りです...」
↑
インターネット上の
一般知識から回答
(御社の固有情報は知らない)
× 御社のマニュアルの内容は答えられない
× 過去のトラブル事例は参照できない
× 一般論しか返ってこない
【パターンB: 業務特化AI(RAG = ナレッジの番人)】
社員の質問 回答
「うちの溶接工程の ──→ 「御社のライン3溶接工程では
注意点は?」 以下の3点が重要です。
過去のトラブル事例として
2024年8月の事例が...」
↑
御社のナレッジベースから
固有情報を検索して回答
(御社専用のAI)
○ 御社のマニュアルを参照して回答
○ 過去のトラブル事例も検索対象
○ 御社専用の「AI社員」として機能| 比較項目 | 汎用AI(ChatGPT等) | RAG(業務特化型AI) |
|---|---|---|
| 学習データ | インターネット上の一般情報 | 自社のマニュアル・事例等 |
| 自社固有の回答 | 不可(一般論のみ) | 可(自社データに基づく回答) |
| 情報の最新性 | 学習時点の情報で固定 | ナレッジベースの更新で即反映 |
| ハルシネーションリスク | 高(自社情報がないため推測で回答) | 低(回答の根拠となるデータを明示) |
| セキュリティ | 入力データがクラウドに送信される | 自社データは自社環境に保管(後述) |
適切に構築されたRAGの回答精度は80〜95%、ハルシネーション率は80〜90%削減されるとされる(AQUA テックブログ)。市場規模はAI活用ナレッジマネジメントシステム全体で2025年に76.6億ドル、2026年には112.4億ドルへの拡大が予測されており(GII調査)、技術的な成熟と導入事例の蓄積が急速に進んでいる。
4. RAPサイクル――社内ナレッジを「使える状態」にし続けるフレームワーク
RAGは構築して終わりではない。これが多くの導入事例で見落とされている点だ。
ナレッジは日々更新される。業務も変化する。「一度登録したら完成」という発想で運用を止めると、半年後には「回答が古くて使えない」という状態になる。
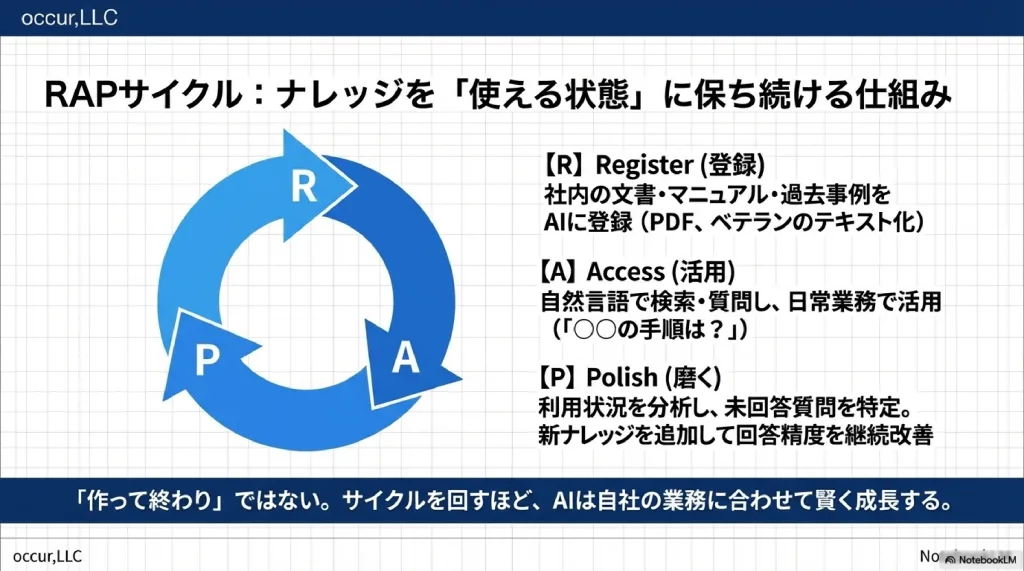
社内ナレッジを「使える状態」に保ち続けるためのフレームワークが、RAPサイクル(Register → Access → Polish)だ。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
RAP サイクル
── 社内ナレッジを「使える状態」にし続けるフレームワーク ──
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
┌──────────┐
│ Register │ 情報を集めて
│ (登録) │ AIに預ける
└─────┬────┘
│
▼
┌──────────┐ ┌──────────┐
│ Polish │ ←─ │ Access │ 自然言語で
│ (磨く) │ │ (活用) │ 検索・活用
└──────────┘ └──────────┘
│
└──→ 利用データを分析し精度を改善
→ 新しいナレッジを追加登録
→ サイクルを回すほど賢くなる| ステップ | 名称 | やること | 業務例 |
|---|---|---|---|
| R | Register(登録) | 社内の文書・マニュアル・過去事例をAIに登録 | マニュアルPDF登録、ベテラン聞き取り結果のテキスト化、FAQ整理 |
| A | Access(活用) | 自然言語で検索・質問し、日常業務で活用 | 「○○の手順は?」「過去の類似事例は?」とチャットで質問 |
| P | Polish(磨く) | 利用状況を分析し、回答精度と登録情報を継続改善 | 月次レポートで未回答質問を特定、新ナレッジを追加登録 |
RAPサイクルの核心は、使うほどAIが賢くなるという点にある。利用者が質問するたびにデータが蓄積され、「よく聞かれるが回答できない質問」が可視化される。そこに新しいナレッジを登録することで、回答精度は着実に向上する。この循環が止まったとき、AIは「使われないマニュアル」と同じ末路をたどる。
5. セキュリティ設計――ハイブリッド型アーキテクチャの仕組み
RAGの導入検討で最も多く寄せられる懸念が、「自社の機密情報がAI事業者に漏れるのではないか」というセキュリティの問題だ。製造業の技術ノウハウ、士業の顧問先情報、医療の患者データ——いずれも外部に出ることが許されない情報を扱う。この懸念は正当であり、設計でしっかりと答えるべき問いだ。
ハイブリッド型アーキテクチャとは
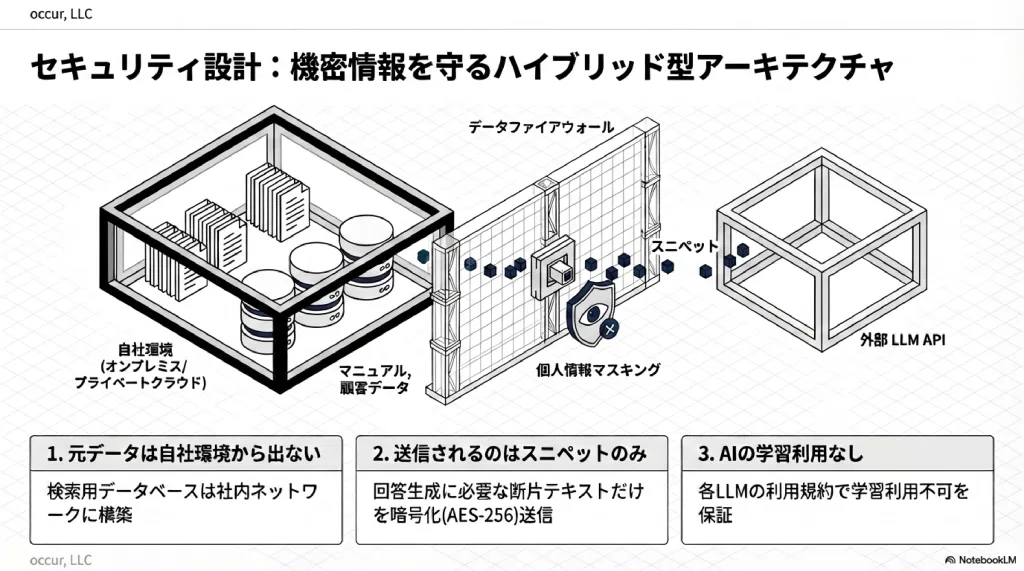
ハイブリッド型アーキテクチャとは、「データの保管場所」と「AIによる回答生成」を分離する設計思想だ。元データは自社環境から一切出ない。外部のAIに送信されるのは、回答生成に必要な断片的なテキスト(スニペット)のみ。この分離が、機密保持の核心にある。
─── ポイント ──────────────────────────────────
1. 御社のデータは御社の環境内に保管(外部送信なし)
2. AIに送られるのは「検索結果のスニペット」だけ
3. AIの学習データには一切使用されない
4. 通信はすべて暗号化 + 個人情報は自動マスキングこの設計の要点を4点に整理する。
- 元データは自社環境から出ない — マニュアル、事例集、顧問先情報、患者データ等の元データは自社の環境(オンプレミスまたはプライベートクラウド)に保管する
- 外部に送信されるのはスニペットのみ — 回答生成を行うLLM APIに送信されるのは、検索結果の断片的なテキストのみ
- AIの学習には使用されない — 送信されたデータがAIの学習に使用されないことは、各LLMプロバイダーの利用規約で保証されている
- 個人情報のマスキング — 送信前に個人名・住所等を自動マスキングする多層防御を設ける
業種別のセキュリティ配慮
| 業種 | 保護すべき情報 | ハイブリッド型での対応 |
|---|---|---|
| 製造業 | 技術ノウハウ、品質データ、設備情報 | 全データを社内環境に保管。API送信は回答生成に必要な最小限のスニペットのみ |
| 士業 | 顧問先情報、案件データ、依頼者の秘密 | 守秘義務に配慮した設計。元データは事務所環境内で完結。アクセス権限を案件単位で設定可能 |
| 医療 | 患者データ、カルテ情報、ケア記録 | 患者の個人情報は施設環境内にのみ保管。前処理マスキングとリアルタイムマスキングの二重防御 |
セキュリティ仕様の詳細
| 項目 | 仕様 |
|---|---|
| データ保管 | 自社環境内(オンプレミスまたはプライベートクラウド)で完結 |
| アクセス権限 | 部署・役職ごとに閲覧範囲を設定(RBAC対応) |
| 操作ログ | 全操作を記録。監査対応可能 |
| 通信暗号化 | TLS 1.3 |
| データ暗号化 | AES-256 |
| 個人情報マスキング | 前処理マスキング + リアルタイムマスキングの多層防御 |
| API学習利用 | なし(各プロバイダーの利用規約で保証) |
6. 導入の具体的なステップ(最短5週間の導入プロセス)
RAG導入は「大がかりなITプロジェクト」ではない。最短5週間で運用を開始し、その後6ヶ月かけて現場に定着させる——これが現実的なタイムラインだ。
Phase 1: ヒアリング・現状分析(1〜2週間)
まず、現在の業務フローとナレッジの現状を把握する。
- 現場の課題ヒアリング(どの業務で、どんな情報を、どれくらいの時間をかけて探しているか)
- 既存ドキュメントの棚卸し(マニュアル・事例集・テンプレート等の所在と状態)
- 対象業務の優先順位付け(最もインパクトが大きく、かつ実現しやすい領域の選定)
このフェーズでの現場への負担は最小限だ。必要なのは2〜3回のヒアリングへの協力のみ。
Phase 2: データ整備・AI構築(2〜3週間)
優先度の高いナレッジをデジタル化し、AIの環境を構築する。
- マニュアル・事例集等のデータ登録(紙の文書のデジタル化を含む)
- 検索用データベースの構築と設定
- AIモデルのチューニング(業種・業務に合わせた回答精度の調整)
- セキュリティ設定(アクセス権限、マスキングルール等)
データ整備とAI構築は、導入を支援する技術者が主導して進める。
Phase 3: テスト運用・調整(1〜2週間)
一部のメンバーで先行的にテスト運用を行い、回答精度と使い勝手を検証する。
| 業種 | テスト運用の着眼点 |
|---|---|
| 製造業 | ベテラン技術者がテストし、回答内容の正確性を検証。現場の言い回しで質問して意図通りの回答が返るか確認 |
| 士業 | 判例検索の精度を検証。過去に扱った案件を再検索し、関連する判例・対応履歴が正しく抽出されるか確認 |
| 医療 | 夜勤帯を想定したテストを実施。急変対応や感染症対応の手順が正確に回答されるか、タブレット操作で確認 |
Phase 4: 全社展開・研修(1週間)
テスト運用の結果をもとに、全社展開を行う。
- 全社員向け操作説明会(実務に即したハンズオン形式)
- チャンピオン(社内AI推進役)の選出と育成
- 利用ルールの策定と周知
操作は「チャットで日本語の質問を入力する」だけのシンプルな設計のため、ITに不慣れなスタッフでも短時間で使い始められる。
Phase 5: 定着支援(6ヶ月間の伴走)
導入後こそが、最も重要なフェーズだ。
DXプロジェクトの失敗事例を分析すると、技術の問題よりも「導入後に使われなくなる」ことが最大の失敗要因として繰り返し報告されている(McKinsey Digital等)。定着のための継続的な支援が不可欠な理由はここにある。
| 時期 | 実施内容 |
|---|---|
| 導入直後(1〜3ヶ月目) | 週次フォローアップ。利用状況の確認、操作サポート、回答精度の継続改善 |
| 安定期(4〜6ヶ月目) | 月次レポート+改善提案。活用部門と未活用部門の可視化、新たな活用シーンの提案 |
| 自走期(7ヶ月目以降) | 月次のAI顧問サービス。ナレッジベースの拡充支援、効果測定、横展開の提案 |
定着において特に効果的な取り組みが3つある。
利用状況の可視化:「誰が・いつ・どんな質問をしているか」をダッシュボードで可視化する。活用が進んでいない部門には、原因を特定してピンポイントで改善策を講じる。
成功体験の共有:「マニュアル検索が月10時間から2時間に減った」「トラブル対応が30分短縮された」といった成功事例を全社に共有し、利用のモチベーションを維持する。
ナレッジベースの継続拡充:新しいマニュアル、新しいトラブル事例、新しい判例など、日々の業務で発生するナレッジを継続的にデータベースに追加する。RAPサイクルを止めないことが、長期的な価値の源泉になる。
3業種の導入ステップ比較表
| 導入Phase | 共通ステップ | 製造業の固有ポイント | 士業の固有ポイント | 医療の固有ポイント |
|---|---|---|---|---|
| Phase 1(1〜2週) | ヒアリング・現状分析 | 現場の動線・シフト体制を考慮 | 守秘義務に配慮した情報整理 | 夜勤帯を含むシフト調査 |
| Phase 2(2〜3週) | データ整備・AI構築 | ベテラン聞き取り+紙文書のデジタル化 | 判例DB・過去案件の構造化 | マニュアル+ケア記録テンプレ化 |
| Phase 3(1〜2週) | テスト運用・調整 | 現場タブレットでの操作検証 | 先生方による回答精度検証 | 日勤・夜勤の両シフトで検証 |
| Phase 4(1週) | 全社展開・研修 | シフト分割型研修 | 業務の合間の短時間研修 | シフトごとの研修実施 |
| Phase 5(継続) | 定着支援・AI顧問 | 品質改善提案・技術伝承進捗レポート | 法改正アップデート配信 | 制度改定ブリーフィング |
| 所要期間 | 最短5週間 | 同左 | 同左 | 同左 |
| 伴走期間 | 6ヶ月 | 同左 | 同左 | 同左 |
| 月額 | 5〜30万円 | 同左 | 同左 | 同左 |
7. 3業種の具体的な活用シーン
製造業の活用シーン
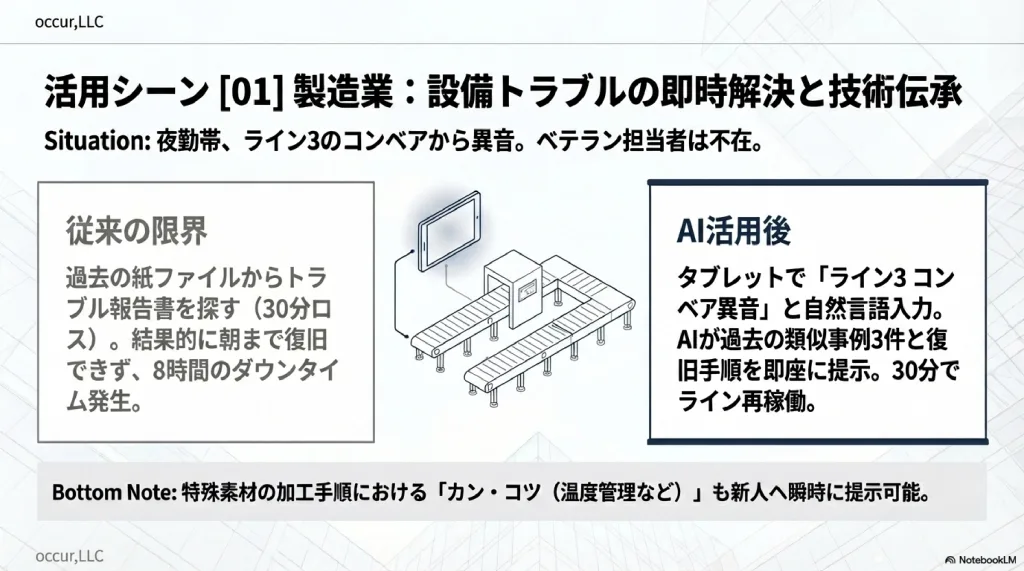
シーン1: 設備トラブルの即時対応
夜勤帯に、ライン3のコンベアから異音が発生して停止。ベテランの山田さんは本日不在。
従来の対応では、山田さんに電話するが繋がらず、過去のトラブル報告書を紙のファイルから探すだけで30分以上かかる。結局、翌朝まで復旧を待つことになり、ダウンタイムは8時間に及ぶ。
AIナレッジ活用後は、タブレットで「ライン3 コンベア 異音 停止」と入力するだけで、過去の類似事例3件と対処手順が即座に表示される。表示された手順に従い、30分で復旧できる。
シーン2: 新人教育の効率化
入社3ヶ月の新人が特殊素材の加工手順で迷っている。従来であれば先輩に質問するしかなく、先輩も自分の作業を中断して対応する——双方に時間コストが発生する構造だ。
AIナレッジ活用後は「○○素材の加工手順と注意点」と入力するだけで、ベテランのノウハウを構造化した手順書が表示される。「この素材は温度が上がりすぎると反りが出るので○○度以下で加工する」といったカン・コツまで含めて確認できる。
士業の活用シーン

シーン1: 判例リサーチの効率化
不動産の瑕疵担保責任に関する判例を調べたい場面。従来は複数の判例データベースを横断してキーワードを試行錯誤しながら2時間、さらに事務所内の類似案件を探すのに1時間——合計3時間がかかることも珍しくない。
AIナレッジ活用後は「瑕疵担保責任に関する最近の判例と、当事務所での類似案件を教えて」と入力するだけで関連判例の一覧と過去案件の対応経緯が即座に表示され、リサーチ時間が30分に短縮される(当社調べ:68%削減)。
シーン2: 担当交代時の引き継ぎ
A社担当の先生が産休に入る。従来の引き継ぎでは資料作成に1週間かかり、それでも「A社はここを気にする」といった暗黙知は伝えきれない。
「A社の過去の相談内容と対応履歴、特記事項をまとめて」と入力するだけで、対応履歴・過去の論点・注意事項が一覧表示される。後任の先生がいつでもAIに「A社について」質問できる体制が、引き継ぎと同時に構築される。
医療の活用シーン
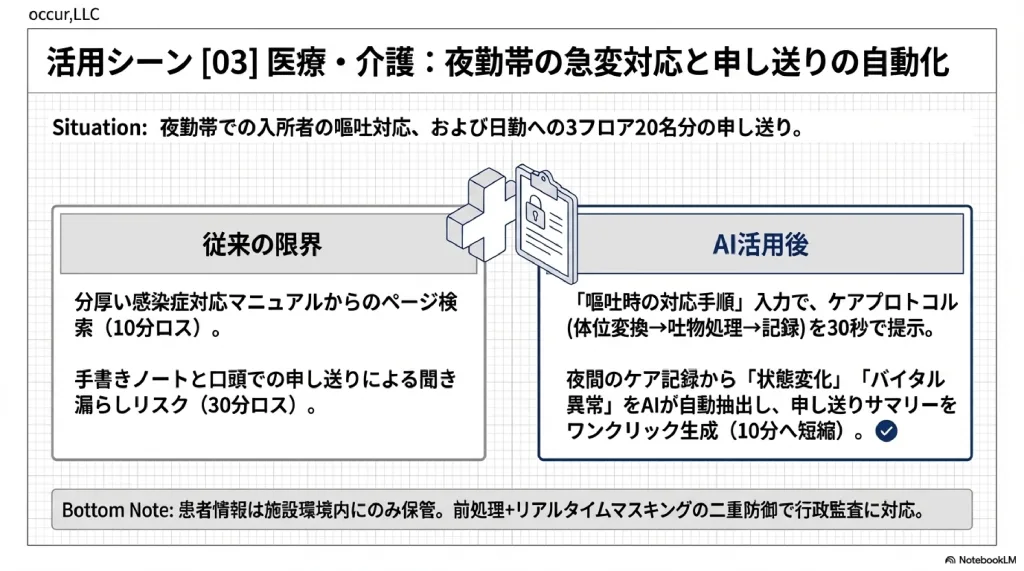
シーン1: 夜勤帯のマニュアル即答
夜勤帯に入所者が嘔吐。経験の浅い介護士が対応する場面。従来はマニュアルのファイルを棚から探し、該当ページを見つけるまでに10分以上かかる。対応が遅れるリスクは小さくない。
AIナレッジ活用後は「嘔吐時の対応手順」と入力するだけで、体位変換→吐物処理→バイタルチェック→記録→報告の手順が即表示される。対応開始まで30秒。
シーン2: 申し送りの確実な伝達
夜勤から日勤への申し送りで、3フロア20名の情報を漏れなく伝達するのは容易ではない。手書きノートでは記入漏れのリスクがあり、口頭申し送りでは聞き漏らしが起きる。申し送り時間は30分かかっていた。
AIナレッジ活用後は、夜間のケア記録から「状態変化」「バイタル異常」「特記事項」を自動抽出し、申し送りサマリーをワンクリックで生成する。申し送り時間は10分に短縮され、内容の確認と補足に集中できる。
3業種の「AIで検索・活用」できる情報と効果

| 項目 | 製造業 | 士業 | 医療・介護 |
|---|---|---|---|
| AIに登録する主な情報 | 作業手順書、設備トラブル事例、品質基準、ベテランの聞き取り記録 | 判例データ、法令・通達、過去案件記録、契約書テンプレート | ケアマニュアル、申し送り記録、ケアプラン、研修資料 |
| よくある質問(活用例) | 「○○製品の組み立て手順は?」「ライン3の異音の過去事例は?」 | 「この論点の過去判例は?」「A社の対応履歴を教えて」 | 「嘔吐時の対応手順は?」「Aさんのケアプラン目標は?」 |
| 検索時間の削減 | -75%(20h→5h/月・人) | -68%(25h→8h/月・人) | -80%(10h→2h/月・人) |
| 書類作成時間の削減 | -67%(15h→5h/月・人) | -67%(30h→10h/月・人) | -60%(25h→10h/月・人) |
| 年間創出時間(1人あたり) | 696時間 ※1 | 804時間 ※2 | 624時間 ※3 |
| セキュリティ上の特殊要件 | 技術ノウハウ・品質データの機密保持 | 守秘義務・依頼者秘匿特権への配慮 | 患者・利用者の個人情報保護(行政監査対応) |
※1 製造業:月削減時間58h × 12ヶ月。年間換算の経済効果は時給3,000円(技術職平均)で計算すると約209万円。
※2 士業:月削減時間67h × 12ヶ月。時給3,000円換算で約241万円。
※3 医療:月削減時間52h × 12ヶ月。時給2,500円換算で約187万円。
(いずれも当社調査。業種・企業規模・業務内容により変動します)
8. まとめ
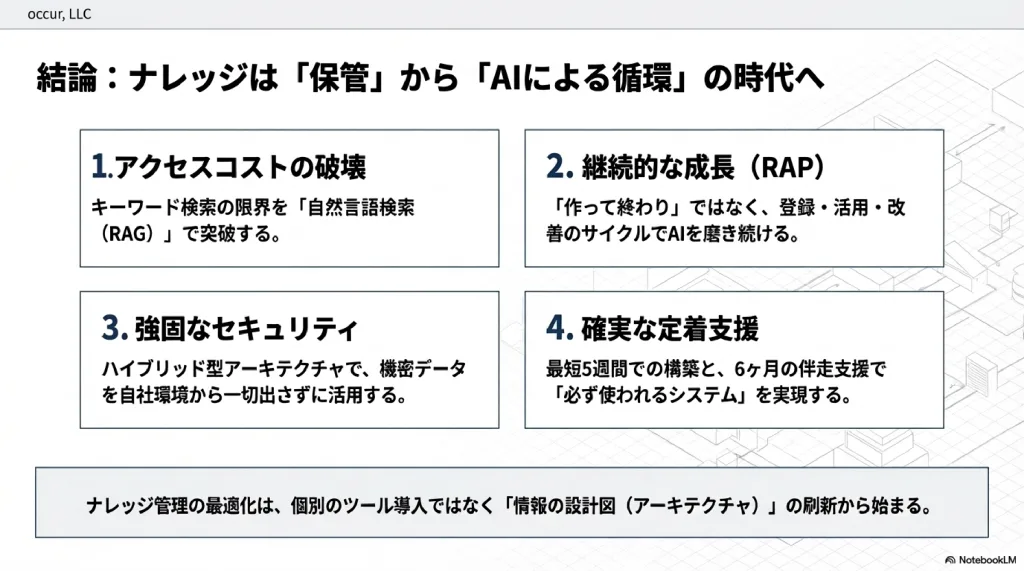
本記事で解説した内容を4点に整理する。
「マニュアルが使われない」問題の本質は、情報へのアクセスコストの高さにある。キーワード検索では越えられない「語彙の壁」を、意味ベースの自然言語検索が超える。これがRAG技術の核心だ。
RAPサイクルを回し続けることが、長期的な価値を生む。構築して終わりではなく、登録(Register)→活用(Access)→改善(Polish)の循環を止めないこと。使うほど賢くなる設計が、投資対効果を高め続ける。
セキュリティの懸念は、ハイブリッド型アーキテクチャで解消できる。元データは自社環境に保管され、外部AIにはスニペットのみが送信される。製造業の技術ノウハウ、士業の顧問先情報、医療の患者データも、この設計であれば安全に活用できる。
導入は最短5週間で開始でき、6ヶ月の伴走で定着させる。大がかりなプロジェクトは不要だ。重要なのは、導入後にチャンピオン制度・利用状況の可視化・ナレッジの継続拡充を機能させること。「使い続ける仕組み」が、結果を左右する。
自社の業務でRAGがどう機能するかを具体的に確認したい方は、業種・業務内容に応じた個別のヒアリングから始めることをお勧めする。現状のナレッジ課題の整理だけでも、次の一手が見えてくるはずだ。
本記事は、ナレッジ管理とAI活用に関する知見を体系的に整理したメソッド記事です。具体的な導入検討に際しては、自社の業務特性と課題に応じた個別の設計が必要です。
出典・参考データ:Iterators(IDC調査)、AQUA テックブログ、GII市場調査レポート、McKinsey Digital