
目次
1. 「マニュアルはあるのに使われない」問題の本質
RAGの導入検討で最も多く寄せられる懸念が、「自社の機密情報がAI事業者に漏れるのではないか」というセキュリティの問題だ。
この懸念に対する解が、ハイブリッド型アーキテクチャだ。元データは自社環境から一切出ない。外部のAIに送信されるのは、回答生成に必要な断片的なテキスト(スニペット)のみ。この分離が、機密保持の核心にある。
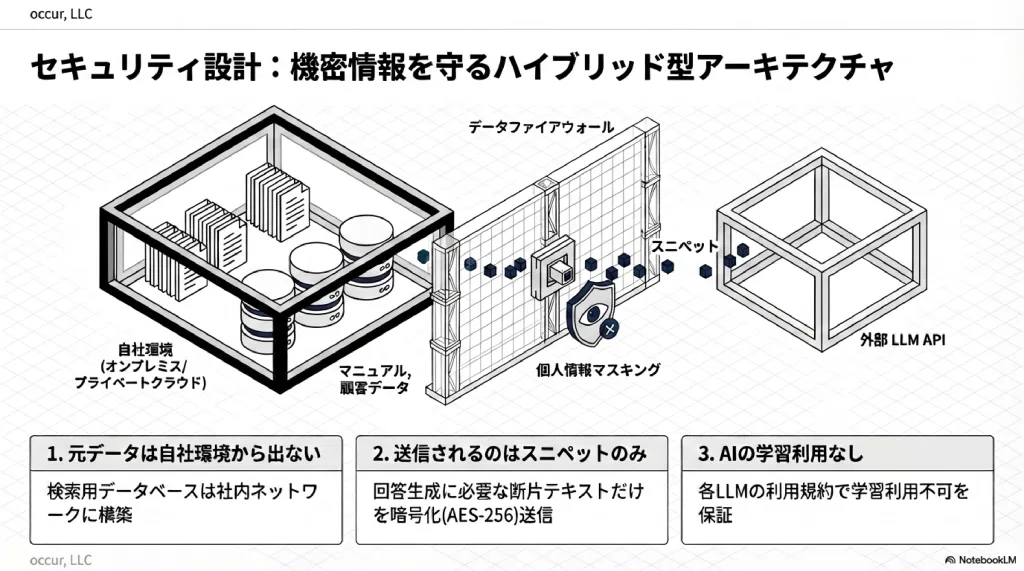
セキュリティ設計のポイントを4点に整理する。
- 元データは自社環境から出ない— マニュアル、事例集等の元データは自社環境に保管する
- 外部に送信されるのはスニペットのみ— LLM APIに送信されるのは検索結果の断片のみ
- AIの学習には使用されない— 各LLMプロバイダーの利用規約で保証されている
- 個人情報のマスキング— 送信前に自動マスキングする多層防御を設ける
導入は最短5週間
RAG導入は「大がかりなITプロジェクト」ではない。最短5週間で運用を開始し、その後6ヶ月かけて現場に定着させるのが現実的なタイムラインだ。
| Phase | 期間 | 内容 |
|---|---|---|
| Phase 1 | 1〜2週間 | ヒアリング・現状分析(現場課題の把握、ドキュメント棚卸し) |
| Phase 2 | 2〜3週間 | データ整備・AI構築(ナレッジ登録、検索DB構築、チューニング) |
| Phase 3 | 1〜2週間 | テスト運用・調整(回答精度の検証、使い勝手の改善) |
| Phase 4 | 1週間 | 全社展開・研修(ハンズオン形式の操作説明会) |
| Phase 5 | 6ヶ月 | 定着支援(週次月次フォローアップ、ナレッジ拡充支援) |
具体的な業種別の活用事例については、「AI×ナレッジ管理の導入事例|製造業・法律事務所・介護施設の活用法」で詳しく紹介している。
5. まとめ
本記事で解説した内容を整理する。
「マニュアルが使われない」問題の本質は、情報へのアクセスコストの高さにある。キーワード検索では越えられない「語彙の壁」を、意味ベースの自然言語検索が超える。
RAPサイクルを回し続けることが、長期的な価値を生む。構築して終わりではなく、登録(Register)活用(Access)改善(Polish)の循環を止めないこと。使うほど賢くなる設計が、投資対効果を高め続ける。
セキュリティの懸念は、ハイブリッド型アーキテクチャで解消できる。元データは自社環境に保管され、外部AIにはスニペットのみが送信される。
導入は最短5週間で開始できる。大がかりなプロジェクトは不要だ。重要なのは、導入後に「使い続ける仕組み」を機能させること。
自社の業務でAIナレッジ管理がどう機能するかを具体的に確認したい方は、業種・業務内容に応じた個別のヒアリングから始めることをお勧めする。
本記事は、ナレッジ管理とAI活用に関する知見を体系的に整理したメソッド記事です。具体的な導入検討に際しては、自社の業務特性と課題に応じた個別の設計が必要です。
出典・参考データ:Iterators(IDC調査)、AQUA テックブログ、GII市場調査レポート、McKinsey Digital
費用の目安
| プラン | 費用感 | 向いているケース |
|---|---|---|
| 既製ツール導入支援のみ | 月額5万円〜 | 既存SaaS(ChatGPT Team / Notion AI等)を業務に定着させたい |
| 業務に合わせたカスタムAIツール開発 | 50万円〜(規模により変動) | 独自フロー・独自データに合わせたAIを作りたい |
| 継続運用・改善伴走(保守) | 月額10万円〜 | 導入後の改善・新機能追加・障害対応を継続的に任せたい |
よくあるご質問(FAQ)
Q1 社内にバラバラに散った資料をAIで横断検索するには、まず何から始めるべきですか?
A まずは検索対象にする情報源を1〜2系統に絞ることをおすすめします。いきなり全社の資料を対象にすると精度が上がらず失敗しやすいので、利用頻度が高いフォルダやドキュメントツールから着手し、運用が安定したら対象を広げる進め方が現実的です。
Q2 既存のNotion・Google Driveをそのまま検索対象にできますか?
A はい、APIコネクタ経由で連携可能です。ただし事前に「情報の粒度」「置き場所のルール」を整理しておかないと精度は出ません。初回相談でドキュメント構造の棚卸しからご支援します。
Q3 導入までどれくらいかかりますか?
A 既製ツール導入支援は最短2週間、カスタム開発は規模により1〜3ヶ月が目安です。初回無料相談時にスケジュール感をお出しします。
Q4 うちの業務データで本当に動きますか?
A 初回相談でサンプルデータをお預かりし、PoC(概念実証)で動作を確認してから本開発に進むプロセスを推奨しています。PoCは10〜30万円程度から実施可能です。
Q5 導入後のサポートはありますか?
A 月額10万円〜の運用伴走プランをご用意しています。LLMモデル更新への追従、精度改善、ユーザー教育まで一貫してお任せいただけます。
occurの関連実装実績
本記事で紹介した方法論は、以下の実装プロジェクトで培ったノウハウをもとに構成しています。
本記事の位置づけ
本記事は 社内ナレッジ管理/RAG領域における AI活用の一例を、occurが設計・実装してきたAI自動化ノウハウをもとに方法論として紹介するものです。
- 記事中の業務フロー・効果試算は一般的なモデルケースであり、特定クライアントの実務実績ではありません。
- 実際の導入には、貴社の業務フロー・データ・既存システムに合わせたカスタマイズが必要です。
- occurが手がける議事録SaaS TalkLog もご覧ください。
TL;DR(結論)
- 社内ナレッジ管理AIは「検索」より「情報の置き場所と粒度の設計」が先。
- RAGの初期精度は60〜70点が一般的。運用で80〜90点へ育てる前提が現実解。
- 既製SaaS(Notion AI等)+カスタムRAGの組み合わせで、月額5万円〜導入可能。
目次
1. 「マニュアルはあるのに使われない」問題の本質
RAGの導入検討で最も多く寄せられる懸念が、「自社の機密情報がAI事業者に漏れるのではないか」というセキュリティの問題だ。
この懸念に対する解が、ハイブリッド型アーキテクチャだ。元データは自社環境から一切出ない。外部のAIに送信されるのは、回答生成に必要な断片的なテキスト(スニペット)のみ。この分離が、機密保持の核心にある。
セキュリティ設計のポイントを4点に整理する。
- 元データは自社環境から出ない— マニュアル、事例集等の元データは自社環境に保管する
- 外部に送信されるのはスニペットのみ— LLM APIに送信されるのは検索結果の断片のみ
- AIの学習には使用されない— 各LLMプロバイダーの利用規約で保証されている
- 個人情報のマスキング— 送信前に自動マスキングする多層防御を設ける
導入は最短5週間
RAG導入は「大がかりなITプロジェクト」ではない。最短5週間で運用を開始し、その後6ヶ月かけて現場に定着させるのが現実的なタイムラインだ。
| Phase | 期間 | 内容 |
|---|---|---|
| Phase 1 | 1〜2週間 | ヒアリング・現状分析(現場課題の把握、ドキュメント棚卸し) |
| Phase 2 | 2〜3週間 | データ整備・AI構築(ナレッジ登録、検索DB構築、チューニング) |
| Phase 3 | 1〜2週間 | テスト運用・調整(回答精度の検証、使い勝手の改善) |
| Phase 4 | 1週間 | 全社展開・研修(ハンズオン形式の操作説明会) |
| Phase 5 | 6ヶ月 | 定着支援(週次月次フォローアップ、ナレッジ拡充支援) |
具体的な業種別の活用事例については、「AI×ナレッジ管理の導入事例|製造業・法律事務所・介護施設の活用法」で詳しく紹介している。
5. まとめ
本記事で解説した内容を整理する。
「マニュアルが使われない」問題の本質は、情報へのアクセスコストの高さにある。キーワード検索では越えられない「語彙の壁」を、意味ベースの自然言語検索が超える。
RAPサイクルを回し続けることが、長期的な価値を生む。構築して終わりではなく、登録(Register)活用(Access)改善(Polish)の循環を止めないこと。使うほど賢くなる設計が、投資対効果を高め続ける。
セキュリティの懸念は、ハイブリッド型アーキテクチャで解消できる。元データは自社環境に保管され、外部AIにはスニペットのみが送信される。
導入は最短5週間で開始できる。大がかりなプロジェクトは不要だ。重要なのは、導入後に「使い続ける仕組み」を機能させること。
自社の業務でAIナレッジ管理がどう機能するかを具体的に確認したい方は、業種・業務内容に応じた個別のヒアリングから始めることをお勧めする。
本記事は、ナレッジ管理とAI活用に関する知見を体系的に整理したメソッド記事です。具体的な導入検討に際しては、自社の業務特性と課題に応じた個別の設計が必要です。
出典・参考データ:Iterators(IDC調査)、AQUA テックブログ、GII市場調査レポート、McKinsey Digital
費用の目安
| プラン | 費用感 | 向いているケース |
|---|---|---|
| 既製ツール導入支援のみ | 月額5万円〜 | 既存SaaS(ChatGPT Team / Notion AI等)を業務に定着させたい |
| 業務に合わせたカスタムAIツール開発 | 50万円〜(規模により変動) | 独自フロー・独自データに合わせたAIを作りたい |
| 継続運用・改善伴走(保守) | 月額10万円〜 | 導入後の改善・新機能追加・障害対応を継続的に任せたい |
よくあるご質問(FAQ)
Q1 社内にバラバラに散った資料をAIで横断検索するには、まず何から始めるべきですか?
A まずは検索対象にする情報源を1〜2系統に絞ることをおすすめします。いきなり全社の資料を対象にすると精度が上がらず失敗しやすいので、利用頻度が高いフォルダやドキュメントツールから着手し、運用が安定したら対象を広げる進め方が現実的です。
Q2 既存のNotion・Google Driveをそのまま検索対象にできますか?
A はい、APIコネクタ経由で連携可能です。ただし事前に「情報の粒度」「置き場所のルール」を整理しておかないと精度は出ません。初回相談でドキュメント構造の棚卸しからご支援します。
Q3 導入までどれくらいかかりますか?
A 既製ツール導入支援は最短2週間、カスタム開発は規模により1〜3ヶ月が目安です。初回無料相談時にスケジュール感をお出しします。
Q4 うちの業務データで本当に動きますか?
A 初回相談でサンプルデータをお預かりし、PoC(概念実証)で動作を確認してから本開発に進むプロセスを推奨しています。PoCは10〜30万円程度から実施可能です。
Q5 導入後のサポートはありますか?
A 月額10万円〜の運用伴走プランをご用意しています。LLMモデル更新への追従、精度改善、ユーザー教育まで一貫してお任せいただけます。
occurの関連実装実績
本記事で紹介した方法論は、以下の実装プロジェクトで培ったノウハウをもとに構成しています。


